文件 ¶
约 1188 个字 96 行代码 1 张图片 预计阅读时间 6 分钟
文件操作 ¶
打开 ¶
fileobj = open(filename,mode)
fileobj是open()返回的文件对象filename是该文件的文件名mode是指明文件类型和操作的字符串mode的第一个字母表明对其的操作mode的第二个字母是文件类型:t(可省略)代表文本类型文件b代表二进制类型文件
| 文件打开模式 | 含义 |
|---|---|
"r" |
read 只读模式 ( 默认 ) |
"w" |
write 覆盖写模式 ( 不存在则新创建;存在则重写新内容 ) |
"a" |
append 追加模式 ( 不存在则新创建;存在则只追加内容 ) |
"x" |
create 创建写模式 ( 不存在则新创建;存在则出错 ) |
"+" |
与 r/w/a/x 一起使用,增加读写功能 |
"t" |
文本类型 |
"b" |
二进制类型 |
文件读写函数 ¶
## 文件迭代器
f = open("1.txt","r")
for i in f:
XXXX
| 名称 | 含义 |
|---|---|
open() |
打开文件 |
read(size) |
从文件读取长度为 size 的字符串,如果未给定或为负则读取所有内容 |
readline() |
读取整行,返回字符串 |
readlines() |
读取所有行并返回列表 |
write(s) |
把字符串 s 的内容写入文件 |
writelines(s) |
向文件写入一个元素为字符串的列表,如果需要换行则要自己加入每行的换行符 |
seek(off, whence=0) |
设置文件当前位置 |
tell() |
返回文件读写的当前位置 |
close() |
关闭文件。关闭后文件不能再进行读写操作 |
文件与异常 ¶
try:
f = open('xxx')
except:
print('fail to open')
finally:
f.close()
- with 方法
with open("1.txt") as file:
data = file.read()
with open('1.txt') as f1, open('2.txt') as f2:
do something
- 紧跟
with后面的表达式被求值后,将调用返回对象的__enter__(),然后将函数的返回值赋值给as后面的变量 - 当
with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法
常见文件格式详解 ¶
CSV (Comma-Separated Values)¶
全称: Comma-Separated Values
特点与格式: - 纯文本格式,以逗号分隔字段 - 每行代表一条记录 - 第一行通常是列名(header) - 示例:
name,age,score
Alice,25,98.5
Bob,30,87.2
Python 使用方法:
import csv
# 读取CSV
with open('data.csv') as f:
reader = csv.DictReader(f)
for row in reader:
print(row['name'], row['age'])
# 写入CSV
with open('output.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['name', 'age'])
writer.writerow(['Alice', 25])
使用场景:
- 深度学习: 存储训练数据的元信息 ( 如图片路径和标签 )
- LLM: 存储问答对训练数据
- CV: 图像分类任务的标签存储
- Control: 记录传感器数据
- 人类可读,简单直观
- 几乎所有数据处理工具都支持
- 体积小
- 不支持复杂数据结构
- 无数据类型定义
- 处理大型文件效率低
XML (eXtensible Markup Language)¶
全称: eXtensible Markup Language
特点与格式:
- 标签式结构化文档
- 支持自定义标签和嵌套结构
<person>
<name>Alice</name>
<age>25</age>
<scores>
<math>98</math>
<english>85</english>
</scores>
</person>
Python 使用方法:
import xml.etree.ElementTree as ET
# 解析XML
tree = ET.parse('data.xml')
root = tree.getroot()
for person in root.findall('person'):
name = person.find('name').text
age = person.find('age').text
# 生成XML
root = ET.Element("people")
person = ET.SubElement(root, "person")
ET.SubElement(person, "name").text = "Alice"
tree = ET.ElementTree(root)
tree.write("output.xml")
使用场景:
- 深度学习: Pascal VOC 等传统 CV 数据集标注
- LLM: 早期知识图谱数据存储
- Control: 工业设备配置文件
优点:
- 强结构化,支持复杂嵌套
- 支持属性定义和命名空间
- 广泛的历史应用基础
缺点:
- 冗长,文件体积大
- 解析速度慢
- 学习曲线较陡
JSON (JavaScript Object Notation)¶
全称: JavaScript Object Notation
特点与格式:
- 轻量级键值对结构
- 支持对象和数组
{
"name": "Alice",
"age": 25,
"scores": {
"math": 98,
"english": 85
}
}
Python 使用方法:
import json
# 读取JSON
with open('data.json') as f:
data = json.load(f)
print(data['name'])
# 写入JSON
data = {"name": "Bob", "age": 30}
with open('output.json', 'w') as f:
json.dump(data, f, indent=2)
- 深度学习: REST API 通信,模型配置
- LLM: 对话记录存储
- CV: COCO 数据集标注格式
- Control: 云端配置同步
- 良好的可读性
- 广泛的语言支持
- 与 JavaScript 无缝交互
- 不支持注释
- 二进制数据需要 Base64 编码
- 大文件解析内存消耗高
YAML (YAML Ain't Markup Language)¶
全称: YAML Ain't Markup Language
特点与格式:
- 使用缩进表示层级
- 支持复杂数据类型
name: Alice
age: 25
scores:
math: 98
english: 85
courses:
- Math
- English
Python 使用方法:
import yaml
# 读取YAML
with open('config.yml') as f:
config = yaml.safe_load(f)
print(config['name'])
# 写入YAML
data = {'name': 'Bob', 'skills': ['Python', 'ML']}
with open('output.yml', 'w') as f:
yaml.dump(data, f, sort_keys=False)
- 深度学习: 训练超参数配置
- LLM: 提示模板管理
- CV: 数据增强配置
- Control: 机器人行为树配置
- 极佳的可读性
- 支持注释和多行字符串
- 丰富的内置数据类型
- 缩进敏感容易出错
- 解析速度比 JSON 慢
- 复杂嵌套可读性下降
对比 ¶
| 格式 | 最佳场景 | 最差场景 | 典型应用案例 |
|---|---|---|---|
| CSV | 表格数据交换 | 嵌套数据结构 | Kaggle 竞赛数据集 |
| XML | 文档标记 | Web API | Pascal VOC 标注 |
| JSON | 配置和 API | 二进制数据 | COCO 数据集格式 |
| YAML | 人类可读配置 | 高性能要求 | HuggingFace 模型配置 |
文件编码 ¶
所有信息都是 01 串,而 01 串之间可以发生互相的转换
常见的 01 串转换方式有 编解码、加解密、哈希
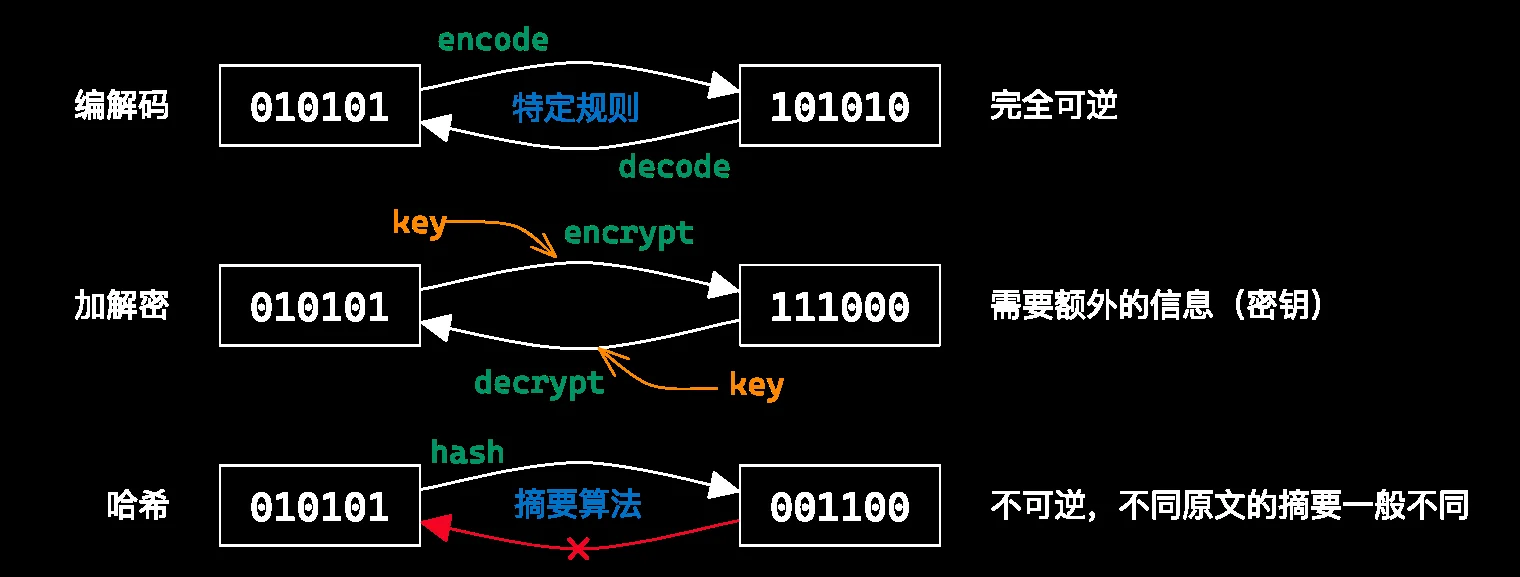
具体参考 MISC 部分的笔记
- ANSI 编码:
- Windows 常用的编码
- UTF-8 编码:
- UTF-8 是缺省编码格式
- 中文编码:
- GB2312,GBK
- Windows 可在 cmd 下用
chcp命令查看 - 默认会以本地编码打开文件
- 打开编码为 GBK 的文件:
open(<文件名>,<模式>,encoding='GBK')
重定向 ¶
sys.stdin标准输入sys.stdout标准输出sys.stderr标准错误输出
import sys
s=sys.stdin.readlines() #从文件读入变为从键盘输入
print(s)